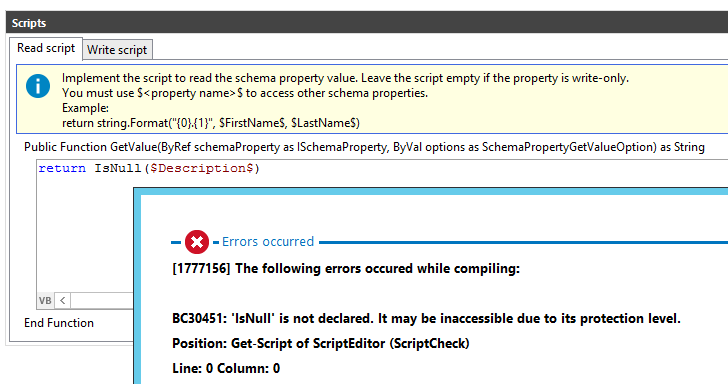

I am not finding any documentation that discusses the available scripts, objects, and functions that are able to be referenced from within a synchronization engine mapping script. I would like to be able to reference the custom schema type (filter), the mapping object name, or other properties of the mapping or workflow that should be available at run time. The goal in this scenario is to be able to connect to an LDAP system that doesn't natively have groups exposed. I have created a custom filtered schema class and a mapping that references the new class, but the value for vrtStructuralObjectClass (in browse) shows the parent schema class instead of the one selected during the mapping creation. I need some way of determining which mapping is currently running so that I can use that information in a property mapping script (OU selection).
- Products
- Solutions
- Resources
- Trials
- Support
- Partners
- Communities